ELLIS PhD School LS-AI projects
During the Summer School, students will have the exciting opportunity to collaborate on group projects, with a maximum group size of 5-6 individuals. These projects will utilize the powerful GPU resources available for training large-scale architectures. Specifically, students will gain access to the Booster partition of the Leonardo Supercomputer, boasting 3456 computing nodes, each armed with four NVIDIA Ampere GPUs with 64GB of memory, delivering an impressive 89.4 TFLOPs peak performance per node. Notably, for the duration of the School, CINECA has reserved 500 Ampere GPUs for three days.
The focal point of the ELLIS PhD School Large Scale-AI (LS-AI) project is highly challenging: students are tasked with proposing and implementing modifications to known algorithms and solutions on a provided dataset using the Leonardo HPC infrastructure. The top three projects will earn the title of winner of the ELLIS PhD School LS-AI project, accompanied by a formal certificate and recognition from the ELLIS School.


Schedule and procedure:
- Prior to the start of the School, you will receive an onboarding form where you can express your interest in taking on the challenge.
- You will have the opportunity to select your preferred projects from six available tracks, ranking them in order of interest. Project descriptions will include details about the data, the subject matter, and references to one or more papers. Data and code will be preloaded onto Leonardo. If you participate, you will receive a Leonardo account for the three days of work.
- Groups will be formed based on student preferences, diversity, and backgrounds. We’ll also make an effort to ensure diversity and avoid grouping students from the same lab.
- Group assignments will be communicated the Friday before the School begins, allowing you to start brainstorming and sharing ideas. You don’t need to propose a groundbreaking idea; a small proposal that can be tested in a few days of coding will suffice.
- A tutorial by NVIDIA and CINECA will take place on the first day of lectures, providing guidance and tips for using the Leonardo Supercomputer. On Monday afternoon, you’ll have time (and a designated space in the library) to collaborate within your groups, start designing and developing your projects, and prepare presentations along with related works and bibliographies.
- During the central days of the School (Tuesday, Wednesday, Thursday), you’ll have access to Parallel GPUs. Please manage your time wisely, keeping in mind:
- Lecture attendance is mandatory for getting credits, with at least 80% attendance expected.
- Time is limited, as the School schedule is intensive.
- Leonardo is available 24/7.
- You’ll need to prepare a concise report and presentation slides.
- The last day of the School includes dedicated slots for each group to present their projects. On Friday evening, a jury will select the three winning projects. The names of the winners will be posted on the School’s website and promoted on the ELLIS website.
- Finally, on Saturday, you can relax 😀
Project tracks
Efficient Foundation Model Training Using FLIP
Vision-language foundation models like CLIP [1] are usually trained using huge training datasets composed of images paired with their textual description. For instance, in CLIP, the visual encoder and the textual encoder represent an image and its textual description using two corresponding vectors, whose mutual cosine similarity is maximized using a contrastive loss. However, the training time of these models is very expensive, with thousands of GPU-days. In [2], the authors propose FLIP, in which training is largely sped up using a Masked Autoencoder (MAE) paradigm [3]. Specifically, similarly to [3], at training time, the visual encoder of FLIP represents only a random subset of visible image patches. Training is still based on a contrastive loss, where the (average pooled) representation of the visible patches is compared with the representation of the image textual description. However, representing only a subset of the image patches leads to a large training speedup and to a lower memory footprint, where the latter is exploited using a larger batch size, which is known to be particularly helpful with a contrastive loss.
The goal of this project is to propose and investigate possible variants of FLIP, including, but not limited to, different (additional) loss functions, different ways to reduce the computational burden or increase the batch size, etc., or to investigate the effects of the dataset size or the batch size in the pretraining phase.
In [4] the students can find an open-source implementation of FLIP, while in [5] they find the LAION-400M dataset used in [2] for pre-training (suggestion: use only a subset of LAION-400M in all your experiments). The encoders of the project should be based on (one of) the ViT architectures adopted in [2].
For testing, the students are encouraged to use one of the two main evaluation protocols adopted in [2], i.e., either Zero-shot accuracy on ImageNet-1K [6] classification or Linear probing on ImageNet-1K classification.
References
[1] A. Radford et al., Learning Transferable Visual Models From Natural Language Supervision, ICML, 2021.
[2] Y. Li et al., Scaling Language-Image Pre-training via Masking, CVPR 2023.
[3] K. He et al., Masked autoencoders are scalable vision learners, CVPR 2022.
[4] FLIP code
[5] LAION dataset
[6] J. Deng et al., ImageNet: A large-scale hierarchical image database, CVPR 2009.
Detecting and Watermarking text generated by Large Language Models
The emergence of large language models (LLMs) has resulted in the production of LLM-generated texts that is highly sophisticated and almost indistinguishable from texts written by humans. However, this has also sparked concerns about the potential misuse of such texts, such as spreading misinformation and causing disruptions in the education system.
A possible solution is that of watermarking the model output [1], i.e., embedding signals into generated text that are invisible to humans but algorithmically detectable from a short span of tokens. In particular, [2] has proposed a watermarking framework for proprietary language models. The watermark can be embedded with negligible impact on text quality, and can be detected using an efficient opensource algorithm without access to the language model API or parameters. The watermark works by selecting a randomized set of “green” tokens before a word is generated, and then softly promoting use of green tokens during sampling.
The objective of the project is to test the effectiveness of the watermark approach presented in [1] (or other works, see [2]) over a variety of open-source available LLMs, discuss its robustness and security. Furthermore, students are challenged with presenting modifications or improvements to the approach presented in [1], to increase its robustness.
References
[1] The Science of Detecting LLM-Generated Texts - https://openreview.net/pdf?id=XLuFNdEsjV2[2] A Watermark for Large Language Models - https://arxiv.org/pdf/2301.10226.pdf
Predicting gene and protein expression levels from DNA and protein sequences exploiting Transformer-based architectures
Background
Living organisms regulate their vital functions through the regulation of biological molecules, in particular proteins. Homo Sapiens has about 20,000 different proteins encoded respectively by as many genes. Each gene (and therefore each protein) is associated with a pair of data, which indicates how that gene/protein is made (i.e., a sequence of letters based on the elements of which it is made up) and how much gene/protein is present (i.e., a discrete number). Quantifying and predicting gene and protein levels (i.e., the discrete number) is crucial to scientific research. The State-of-the-art models (e.g., Xpresso [1]) predict gene expression values exploiting Convolutional (CNN) or Long Short Term Memory (LSTM) Networks. However, CNN prediction depends on convolutional kernel size, and LSTM suffers from capturing long-range dependencies in the sequence. [2] proposes a new model type (Perceiver) for gene and protein level prediction, exploiting a Transformer-based architecture with an attention module to attend to long-range interactions in the sequences. In addition, the Perceiver model overcomes the quadratic complexity of the standard Transformer architectures.
Project aim
The project aims to train and test a Transformer-based architecture for predicting gene and protein expression values from gene and protein sequences. Therefore, sequences are the input to the model; expression values are the outputs. Starting from [2], you have to develop
1. A model to predict gene expression levels from the gene sequence.
2. A model to predict protein expression levels from the protein sequence.
3. A model to simultaneously predict protein expression levels from gene and protein expression.
The students must propose and investigate the Perceiver’s possible variants, e.g., loss functions, model structure, and attention layers.
The evaluation protocol should be based on [2], exploiting the rsup_2_sup metric as an evaluation criteria.
References
[1] Agarwal, Vikram, and Jay Shendure. Predicting mRNA abundance directly from genomic sequence using deep convolutional neural networks. Cell reports 31.7 (2020). Xpresso full paper here
[2] Stefanini, Matteo, et al. Predicting gene and protein expression levels from DNA and protein sequences with Perceiver. Computer Methods and Programs in Biomedicine 234 (2023) 107504. Gene and protein expression Perceiver full paper here
Multi-Instance-Learning (MIL) models to Perform a Multi-Scale Classification of Large Histological Images (WSIs)
Background
The adoption of Multi-Instance Learning (MIL) for classifying Gigapixels histological images (technically named Whole-Slide Images -WSIs-) has increased in recent years. Indeed, due to their size, pixel-level annotation of WSIs is mostly unfeasible and time consuming in practice. For this reason, MIL approaches have been profitably integrated with the most recent deep-learning solutions for WSI classification to support clinical practice and diagnosis. Nevertheless, the majority of such approaches overlook the multi-scale nature of the WSIs; the few existing hierarchical MIL proposals simply flatten the multi-scale representations by concatenation or summation of features vectors, neglecting the spatial structure of the WSI. [1] work aims to unleash the full potential of pyramidal structured WSI; to do so, proposing a graph based multi-scale MIL approach, termed DAS-MIL, that exploits message passing to let information flows across multiple scales. By means of a knowledge distillation schema, the alignment between the latent space representation at different resolutions is encouraged while preserving the diversity in the informative content.
Project aim
The project aims to train and test DAS-MIL for predicting the presence of tumor in histological images, profiting from a multi-scale approach. Therefore, WSIs are the input to the model; tumor/non tumor information is the output. Refer to [1] for model implementation and datasets availability.
The students must propose and investigate DAS-MIL’s possible variants, e.g., loss functions, knowledge distillation, and graph attention layers.
The evaluation protocol should be based on [1], testing results on Camelyon16 dataset and TCGA lung cancer, provided in the dataset link.
References
[1] Bontempo, Gianpaolo, et al. “DAS-MIL: Distilling Across Scales for MILClassification of Histological WSIs.” Medical Image Computing and Computer Assisted Intervention–MICCAI 2023. 2023. DAS-MIL full paper here
Per-Object Distance Estimation from Monocular Images
Among past and novel challenges, the Computer Vision community has a long-standing commitment for 3D visual perception, i.e., seeing the surrounding environment in all three spatial dimensions (including depth). In this respect, humans continuously practice such a capability in everyday life: for example, when approaching a stop sign, the driver visually assesses the remaining distance to the sign and adjusts the car’s velocity accordingly. Such a simple scenario suggests the importance of a reliable 3D automatic perception, especially for AI systems dealing with autonomous driving and video surveillance applications.
While many researchers focused on popular tasks such as object detection and segmentation, a few efforts have been spent on object-specific distance estimation. Herein, the goal is to estimate the distance of a target object from the camera when it is projected onto the image plane. Pioneer works accomplished it with the pinhole model and the standard projective transformation; unfortunately, these approaches are viable only in static scenarios and suffer from radial lens distortion, hindering the estimation for objects located far from the center.
Recent approaches
Instead, modern approaches rely either on geometric and feature-based strategies. The former [2,3,6] treat the problem as a regression task and attempt to learn the relationship, expected to be roughly linear, between the visual size of an object (such as the height of its bounding box) and its distance. In contrast, feature-based approaches [4,5,7] exploit deep learning architectures (e.g., Convolutional Neural Network) and incorporate visual cues of the target object, as well as global information related to the scene.
The project
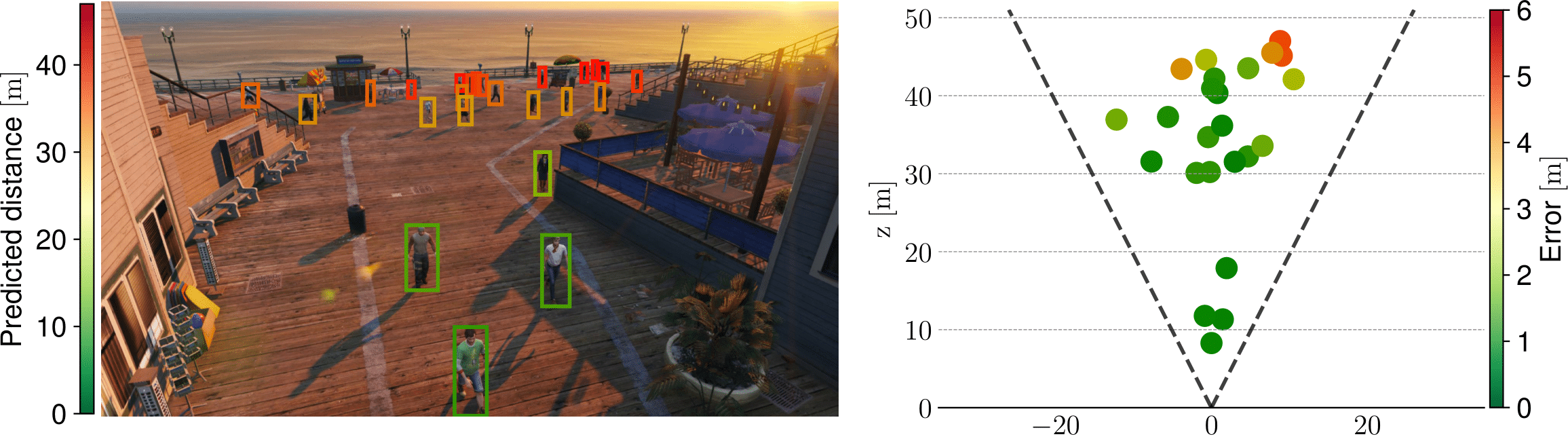
The scope of this project is to investigate and propose an approach for per-object distance estimation given a single image. In more details, the focus of the project is on outdoor urban scenarios: namely, the images come from a security camera filming a public place (e.g., a square or a street), with moving pedestrians and cars. Due to privacy concerns, the project relies on synthetic data only and specifically on MOTSynth [1], a recently released synthetic dataset for pedestrian detection, tracking, and segmentation. To help the students, the bounding boxes of the objects of interests (i.e., pedestrians) will be provided at both training and evaluation time, along with the entire original image.
To allow the students to assess the merits of their proposals, a ready-to-use codebase for both training and evaluation purpose will be released. Moreover, two simple approaches will be provided as baselines:
- DisNet [3], a simple regression-like approach based on Multi Layer Perceptrons (MLPs) that is fed with the relative width, height, and diagonal of bounding boxes. These features are then concatenated with three corresponding reference values (set to 175 cm, 55 cm, and 30 cm).
- The architecture proposed by Zhu et al. [7], which relies on ResNet as feature extractor and RoI pooling to build object-level representations.
The following are just some of the possible directions that the students could investigate:
- The exploitation of modern architectures, such as Graph Neural Networks (GNNs), Vision Transformers (VITs), Swin, and DeIT.
- The exploitation of self-supervised training techniques, such as Masked Autoencoders (MAEs).
- The adoption of techniques of model compression to reduce the computational footprint required at inference time.
References
[1] Fabbri, Matteo, et al. “Motsynth: How can synthetic data help pedestrian detection and tracking?.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[2] Gökçe, Fatih, et al. “Vision-based detection and distance estimation of micro unmanned aerial vehicles.” Sensors 15.9 (2015): 23805-23846.
[3] Haseeb, Muhammad Abdul, et al. “DisNet: a novel method for distance estimation from monocular camera.” 10th Planning, Perception and Navigation for Intelligent Vehicles (PPNIV18), IROS (2018).
[4] Jing, Longlong, et al. “Depth estimation matters most: improving per-object depth estimation for monocular 3D detection and tracking.” 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022.
[5] Li, Yingwei, et al. “R4D: Utilizing Reference Objects for Long-Range Distance Estimation.” arXiv preprint arXiv:2206.04831 (2022).
[6] Tuohy, Shane, et al. “Distance determination for an automobile environment using inverse perspective mapping in OpenCV.” (2010): 100-105.
[7] Zhu, Jing, and Yi Fang. “Learning object-specific distance from a monocular image.” Proceedings of the IEEE/CVF International Conference on computer vision. 2019.
Using Neural Radiance Fields in real scenarios
Using NeRF [1] is it now possible to achieve state-of-the-art results for synthesizing novel views of complex scenes by optimizing an underlying continuous volumetric scene function using a sparse set of input views.
The scene is represented with a deep network, whose input is a single continuous 5D coordinate (spatial location (x, y, z) and viewing direction (θ, φ)) and whose output is the volume density and view-dependent emitted radiance at that spatial location.
A set of images with known camera poses is required. However, the exact camera poses are not available in real scenarios. Thus, a refinement step of the camera poses is mandatory to achive better results.
The project will exploit two publicly available datasets, namely:
- DTU dataset: https://roboimagedata.compute.dtu.dk/?page_id=36
- Replica dataset: https://github.com/cvg/nice-slam/blob/master/scripts/download_replica.sh, https://github.com/facebookresearch/Replica-Dataset
The train a NeRF with an instant NGP backbone [2] on the images, the suggested implementation is available here: https://docs.nerf.studio/en/latest/
References
[1] Ben Mildenhall and Pratul P. Srinivasan and Matthew Tancik and Jonathan T. Barron and Ravi Ramamoorthi and Ren Ng, “NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis”, ECCV 2020
[2] Thomas Müller, Alex Evans, Christoph Schied, Alexander Keller, “Instant Neural Graphics Primitives with a Multiresolution Hash Encoding”, ACM Transactions on Graphics (SIGGRAPH), July 2022